Hello! I am a research scientist at FacebookMeta Research. I work on Bayesian modeling and lead the development of the PyTorch-based Bean Machine probabilistic programming language.
I just finished my Master’s degree at UIUC and will be joining FacebookMeta full-time.
selected publications
Improving natural language inference using external knowledge in the science questions domain
Xiaoyan Wang, Pavan Kapanipathi, Ryan Musa, Mo Yu, Kartik Talamadupula, Ibrahim Abdelaziz, Maria Chang, Achille Fokoue, Bassem Makni, Nicholas Mattei, and Michael Witbrock
In Proceedings of the AAAI Conference on Artificial Intelligence 2019
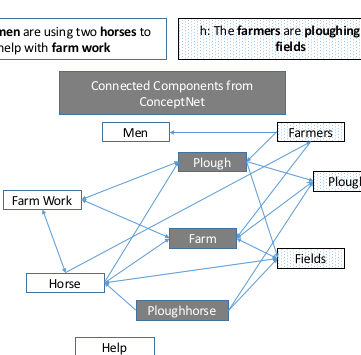
Natural Language Inference (NLI) is fundamental to many Natural Language Processing (NLP) applications including semantic search and question answering. The NLI problem has gained significant attention due to the release of large scale, challenging datasets. Present approaches to the problem largely focus on learning-based methods that use only textual information in order to classify whether a given premise entails, contradicts, or is neutral with respect to a given hypothesis. Surprisingly, the use of methods based on structured knowledge – a central topic in artificial intelligence – has not received much attention vis-a-vis the NLI problem. While there are many open knowledge bases that contain various types of reasoning information, their use for NLI has not been well explored. To address this, we present a combination of techniques that harness external knowledge to improve performance on the NLI problem in the science questions domain. We present the results of applying our techniques on text, graph, and text-and-graph based models; and discuss the implications of using external knowledge to solve the NLI problem. Our model achieves close to state-of-the-art performance for NLI on the SciTail science questions dataset.
@inproceedings{wang2019improving,title={Improving natural language inference using external knowledge in the science questions domain},author={Wang, Xiaoyan and Kapanipathi, Pavan and Musa, Ryan and Yu, Mo and Talamadupula, Kartik and Abdelaziz, Ibrahim and Chang, Maria and Fokoue, Achille and Makni, Bassem and Mattei, Nicholas and Witbrock, Michael},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},volume={33},number={01},pages={7208--7215},year={2019},}
Answering science exam questions using query rewriting with background knowledge
Ryan Musa, Xiaoyan Wang, Achille Fokoue, Nicholas Mattei, Maria Chang, Pavan Kapanipathi, Bassem Makni, Kartik Talamadupula, and Michael Witbrock
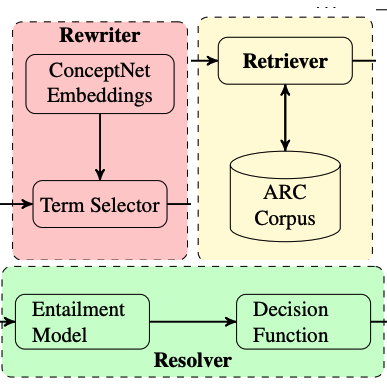
Open-domain question answering (QA) is an important problem in AI and NLP that is emerging as a bellwether for progress on the generalizability of AI methods and techniques. Much of the progress in open-domain QA systems has been realized through advances in information retrieval methods and corpus construction. In this paper, we focus on the recently introduced ARC Challenge dataset, which contains 2,590 multiple choice questions authored for grade-school science exams. These questions are selected to be the most challenging for current QA systems, and current state of the art performance is only slightly better than random chance. We present a system that rewrites a given question into queries that are used to retrieve supporting text from a large corpus of science-related text. Our rewriter is able to incorporate background knowledge from ConceptNet and – in tandem with a generic textual entailment system trained on SciTail that identifies support in the retrieved results – outperforms several strong baselines on the end-to-end QA task despite only being trained to identify essential terms in the original source question. We use a generalizable decision methodology over the retrieved evidence and answer candidates to select the best answer. By combining query rewriting, background knowledge, and textual entailment our system is able to outperform several strong baselines on the ARC dataset.
@inproceedings{musa2019answering,title={Answering science exam questions using query rewriting with background knowledge},author={Musa, Ryan and Wang, Xiaoyan and Fokoue, Achille and Mattei, Nicholas and Chang, Maria and Kapanipathi, Pavan and Makni, Bassem and Talamadupula, Kartik and Witbrock, Michael},booktitle={Automated Knowledge Base Construction},year={2019},}
PPL Bench: Evaluation Framework For Probabilistic Programming Languages
Sourabh Kulkarni, Kinjal Divesh Shah, Nimar Arora, Xiaoyan Wang, Yucen Lily Li, Nazanin Khosravani Tehrani, Michael Tingley, David Noursi, Narjes Torabi, Sepehr Akhavan Masouleh, Eric Lippert, and Erik Meijer
In International Conference on Probabilistic Programming (PROBPROG) 2020
We introduce PPL Bench, a new benchmark for evaluating Probabilistic Programming Languages (PPLs) on a variety of statistical models. The benchmark includes data generation and evaluation code for a number of models as well as implementations in some common PPLs. All of the benchmark code and PPL implementations are available on Github. We welcome contributions of new models and PPLs and as well as improvements in existing PPL implementations. The purpose of the benchmark is two-fold. First, we want researchers as well as conference reviewers to be able to evaluate improvements in PPLs in a standardized setting. Second, we want end users to be able to pick the PPL that is most suited for their modeling application. In particular, we are interested in evaluating the accuracy and speed of convergence of the inferred posterior. Each PPL only needs to provide posterior samples given a model and observation data. The framework automatically computes and plots growth in predictive log-likelihood on held out data in addition to reporting other common metrics such as effective sample size and r_hat
@inproceedings{kulkarni2020ppl,title={PPL Bench: Evaluation Framework For Probabilistic Programming Languages},author={Kulkarni, Sourabh and Shah, Kinjal Divesh and Arora, Nimar and Wang, Xiaoyan and Li, Yucen Lily and Tehrani, Nazanin Khosravani and Tingley, Michael and Noursi, David and Torabi, Narjes and Masouleh, Sepehr Akhavan and Lippert, Eric and Meijer, Erik},booktitle={International Conference on Probabilistic Programming (PROBPROG)},year={2020},}